JSON in Hive 2.3.2 With Hive-JSON-Serde (Load data,Query tables, complex structure)
previous posts: hadoop cluster and hive installation
In this topic we will go through some steps: create local json, load it into hdfs, creation external hive table, queries to this table and etc.
First of all create local json file with notepad or vi, name it js1.json and populate with this data:
In this topic we will go through some steps: create local json, load it into hdfs, creation external hive table, queries to this table and etc.
First of all create local json file with notepad or vi, name it js1.json and populate with this data:
{"ts":1520318907,"device":1,"metric":"p","value":100}
{"ts":1520318908,"device":2,"metric":"p","value":110}
{"ts":1520318909,"device":1,"metric":"v","value":8}
{"ts":1520318910,"device":2,"metric":"v","value":9}
{"ts":1520318911,"device":1,"metric":"p","value":120}
{"ts":1520318912,"device":2,"metric":"p","value":140}
{"ts":1520318913,"device":1,"metric":"v","value":10}
{"ts":1520318914,"device":2,"metric":"v","value":11}
Load this file from local to hdfs. You can use Hadoop web interface or hdfs put command. you can create new directory in HDFS with command:
$ hadoop fs -mkdir /user/data/js_db

$ hadoop fs -ls /user/data/js_db
Found 3 items
-rw-r--r-- 3 dr.who supergroup 438 2018-03-16 09:29 /user/data/js_db/js1.json
-rw-r--r-- 3 dr.who supergroup 438 2018-03-15 15:47 /user/data/js_db/js2.json
-rw-r--r-- 3 dr.who supergroup 334 2018-03-15 15:48 /user/data/js_db/js3.json
Next we need download json SerDe library
[hadoop@hadoop-master lib]$ whoami
hadoop
[hadoop@hadoop-master lib]$ pwd
/opt/hive/lib
[hadoop@hadoop-master lib]$
wget http://www.congiu.net/hive-json-serde/1.3.8/hdp23/json-serde-1.3.8-jar-with-dependencies.jar
restart hiveserver2 (or try hive> ADD JAR json-serde-1.3.8-jar-with-dependencies.jar)
Next step is creating hive table and load json data.
DROP TABLE json1;
CREATE EXTERNAL TABLE default.json1(
ts INTEGER,
device INTEGER,
metric string,
value DOUBLE
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' STORED AS TEXTFILE;
select * from json1
json1.ts |json1.device |json1.metric |json1.value |
---------|-------------|-------------|------------|
LOAD DATA INPATH 'hdfs://10.242.5.88:9000/user/data/js_db/js1.json' OVERWRITE INTO TABLE json1;
Pay attention that now js1.json removed from hdfs.
$ hadoop fs -ls /user/data/js_db
Found 2 items
-rw-r--r-- 3 dr.who supergroup 438 2018-03-16 09:48 /user/data/js_db/js2.json
-rw-r--r-- 3 dr.who supergroup 334 2018-03-16 09:48 /user/data/js_db/js3.json
select * from json1
json1.ts |json1.device |json1.metric |json1.value |
-----------|-------------|-------------|------------|
1520318907 |1 |p |100 |
1520318908 |2 |p |110 |
1520318909 |1 |v |8 |
1520318910 |2 |v |9 |
1520318911 |1 |p |120 |
1520318912 |2 |p |140 |
1520318913 |1 |v |10 |
1520318914 |2 |v |11 |
I use DBeaver for HQL and work with Hive
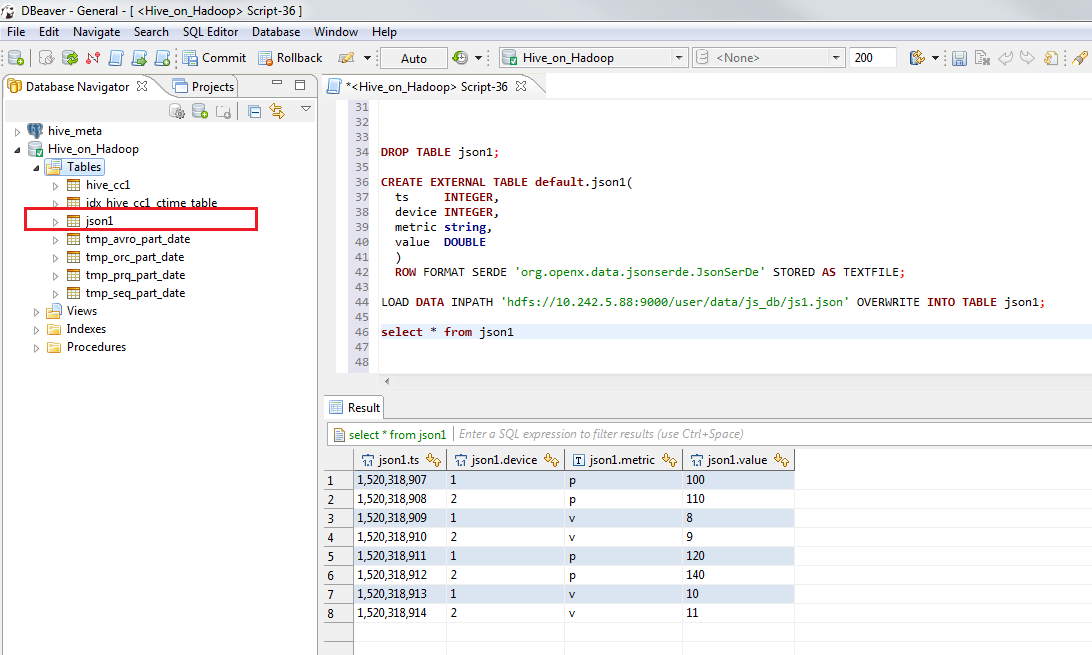
In previous example we create table in Hive and load json into it, the next step is to create Hive table that reads data direct from json file.
DROP DATABASE js_db;
CREATE DATABASE js_db;
DROP TABLE json2;
CREATE EXTERNAL TABLE js_db.json2(
ts INTEGER,
device INTEGER,
metric string,
value DOUBLE
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 'hdfs://10.242.5.88:9000/user/data/js_db';
select * from js_db.json2
json2.ts |json2.device |json2.metric |json2.value |
-----------|-------------|-------------|------------|
1520318907 |1 |p |100 |
1520318908 |2 |p |110 |
1520318909 |1 |v |8 |
1520318910 |2 |v |9 |
1520318911 |1 |p |120 |
1520318912 |2 |p |140 |
1520318913 |1 |v |10 |
1520318914 |2 |v |11 |
1520318907 |1 | |100 |
1520318908 |2 | |110 |
1520318909 |1 | |8 |
1520318910 |2 | |9 |
1520318911 |1 | |120 |
Hive read all json files from location hdfs://10.242.5.88:9000/user/data/js_db And in one file I remove field metric. Hive read it but filed metric is empty.
This approach can be useful if you upload json file into one location frequently, special from different sources, but json with similar structure. For example you can create schedule job that read files from this location and reload it into Hive table and then delete sources.
Example of reading json with more difficult nested structure.
create and upload into hdfs js_nested.json
{"ts":1520318907,"conveyor_num":1, data : [{"metric":"temp","value":120},{"metric":"speed","value":1000}]}
{"ts":1520318907,"conveyor_num":2, data : [{"metric":"temp","value":240},{"metric":"speed","value":1000}]}
{"ts":1520318908,"conveyor_num":1, data : [{"metric":"temp","value":130},{"metric":"speed","value":1200}]}
{"ts":1520318908,"conveyor_num":2, data : [{"metric":"temp","value":260},{"metric":"speed","value":800}]}
DROP TABLE json_nested_test;
CREATE TABLE json_nested_test (
ts INTEGER,
conveyor_num INTEGER,
data array>
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
STORED AS TEXTFILE;
LOAD DATA INPATH 'hdfs://10.242.5.88:9000/user/data/js_db/js_nested.json' OVERWRITE INTO TABLE json_nested_test;
select
nt.ts,
nt.conveyor_num,
nt.data[0].metric,
nt.data[0].value,
nt.data[1].metric,
nt.data[1].value
from
json_nested_test nt
nt.ts |nt.conveyor_num |metric |value |metric |value |
-----------|----------------|-------|------|-------|------|
1520318907 |1 |temp |120 |speed |1000 |
1520318907 |2 |temp |240 |speed |1000 |
1520318908 |1 |temp |130 |speed |1200 |
1520318908 |2 |temp |260 |speed |800 |
more complex query with sum and FILTER
select
nt.conveyor_num,
sum(nt.data[0].value*100 + nt.data[1].value/2) as calc_value
from
json_nested_test nt
where nt.conveyor_num=1
group by nt.conveyor_num
nt.conveyor_num |calc_value |
----------------|-----------|
1 |26100 |
More examples you can find here (Hive-JSON-Serde)



Комментарии
Отправить комментарий